Battery power profiles and performance
One question that I had for a long time was do the power profiles on a
laptop have any real impact?
. While working on this blog’s engine, I had
to compile large Haskell libraries (e.g., pandoc) and I got some
empirical proof that there is some impact. Hence, the question now turned into
how much is performance affected when switching from “performance” to
“power saver” mode?
. Let’s answer this in this article.
Designing the experiments 🔗
I am using NixOs – which is Linux –, within a GNOME environment. This allows me to select between 3 different power profiles: “performance”, “balanced” and “power saver”. Thus, we need to compare across all these modes.
Most (if not all) modern laptops come with multicore CPUs, to perform multithreading. The performance of this could also be affected by battery power profile, hence I will test with single thread programs as well as programs that run on as many threads as the system can run at the same time.
In general, programs can be divided into 2 categories: compute-bound programs – which spend most of their time running code on the CPU, with data from cache –, and I/O-bound programs – which spend most of their time waiting for a peripheral device. There are variations in between, this is not a binary decision but a spectrum. But for the purposes of this study, we’ll only focus on a program that does a lot of computation and a program that read a large number of files from the disk. At some point in the future, I might decide to replicate these experiments with programs that use a GPU as well as programs that access the internet, etc.
For the I/O bound scenario, we need to take into account the operating system’s cache. Hence, I will run this experiment both with a cold filesystem cache (i.e., after a reboot) and with a warm one (i.e., running the same program multiple times in a row before performing an actual measurement).
Finally, to study the impact of battery level, we will repeat the measurements at different battery charge levels, both plugged-in and unplugged.
These are the general things we need to consider for this study. Let’s now write the programs for the test scenarios.
Programs under test 🔗
As discussed, we want one suite of programs that are CPU-bound and one suite of programs that are disk-bound. Each suite contains a version that runs single threaded and a version that runs multi-threaded. I will post the code without much comments, but I also want the change from single-thread to multi-thread to be minimal.
Matrix multiplication 🔗
For the CPU-bound program, I wrote a very naive matrix multiplication in C.
Thus, the programs in this suite are named mm.., where the last 2 letters
relate to whether the program is for a single core (mmsc) or multicore
(mmmc).
The single-threaded program is:
// mmsc.c
#include <stdio.h>
#include <stdlib.h>
#ifndef SZ
#define SZ 10
#endif
int main(void) {
int sz = SZ * SZ;
long long *a = calloc(sz, sizeof(*a));
for (int i = 0; i < sz; i++) a[i] = 1;
a[1] = 0;
long long *b = calloc(sz, sizeof(*b));
for (int i = 0; i < SZ; i++)
for (int j = 0; j < SZ; j++)
for (int k = 0; k < SZ; k++)
b[i * SZ + j] += a[i * SZ + k] * a[k * SZ + j];
long long sa = 0;
for (int i = 0; i < SZ; i++)
for (int j = 0; j < SZ; j++)
sa += b[i * SZ + j];
long long sd = 0;
for (int i = 0; i < SZ; i++)
sd += b[i * SZ + i];
long long esa = (long long)(SZ * SZ) * SZ - 2 * SZ;
long long esd = SZ * SZ - 2;
printf("%lld = %lld || %lld = %lld\n", sa, esa, sd, esd);
free(b);
free(a);
return 0;
}I am basically computing \(B = A^2\) where \(A\) is a matrix of size SZ * SZ
filled with 1, except one element being set to 0:
\[A = \begin{pmatrix} 1 & 0 & 1 & \ldots & 1 \\ 1 & 1 & 1 & \ldots & 1 \\ 1 & 1 & 1 & \ldots & 1 \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & 1 & 1 & \ldots & 1 \end{pmatrix}\]
To check that the multiplication is correct, I compute the sum of all elements and the sum of the elements on the diagonal. It is easy to prove (by induction) that these sums are:
\[\begin{align} s_a &=& \sum_{i=0}^n\sum_{j=0}^n{B_{ij}} &=& n^3 - 2n\\ s_d &=& \sum_{i=0}^n {B_{ii}} &=& n^2 - 2 \end{align}\]
Hence, the end of the program is printing the value of the sum as computed by iterating over the resulting matrix as well as those computed from the formulas above.
The multicore program uses OpenMP for minimal code changes:
diff --git a/mmsc.c b/mmmc.c
index 7531933..4209e09 100644
--- a/mmsc.c
+++ b/mmmc.c
@@ -12,10 +12,12 @@ int main(void) {
a[1] = 0;
long long *b = calloc(sz, sizeof(*b));
+#pragma omp parallel for
for (int i = 0; i < SZ; i++)
for (int j = 0; j < SZ; j++)
for (int k = 0; k < SZ; k++)
b[i * SZ + j] += a[i * SZ + k] * a[k * SZ + j];
+#pragma omp barrier
long long sa = 0;
for (int i = 0; i < SZ; i++)The size parameter is given by a #define as this would allow me to
change the matrix size to have a runtime that is large enough but also not
require me to spend a full day with all the experiments. I settled for a size
of 2048, so the compilation of this suite is as follows:
gcc -Wall -Wextra -O3 -DSZ=2048 mmsc.c -o mmsc
gcc -Wall -Wextra -O3 -fopenmp -DSZ=2048 mmmc.c -o mmmcFile summarization 🔗
For the disk bound program, I wrote a C++ program that would read all files
under a directory and its subdirectories and count the number of occurrences
of the 'a' and 'b' characters. The naming scheme is fs.. (from
file system), followed by sc/mc as above.
The single core directory walk program is:
#include <deque>
#include <filesystem>
#include <fstream>
#include <iostream>
struct PathEntry {
std::string path;
bool isFile;
PathEntry(std::string path_, bool isFile_) : path(path_), isFile(isFile_) {}
PathEntry() : path(""), isFile(false) {}
};
class Processor {
public:
Processor(std::string rootDir);
~Processor();
void Run();
void PrintStats();
private:
void ProcessFile(std::string path);
void ProcessDirectory(std::string path);
int na_, nb_;
std::deque<PathEntry> queue_;
};
Processor::Processor(std::string rootDir) : na_(0), nb_(0) {
queue_.emplace_back(rootDir, false);
}
Processor::~Processor() {
queue_.clear();
}
void Processor::Run() {
while (!queue_.empty()) {
PathEntry entry = queue_.front();
queue_.pop_front();
if (entry.isFile) {
ProcessFile(entry.path);
} else {
ProcessDirectory(entry.path);
}
}
}
void Processor::PrintStats() {
std::cout << na_ << " " << nb_ << "\n";
}
void Processor::ProcessFile(std::string path) {
std::fstream file(path, std::ios::in);
if (!file.is_open()) {
std::cerr << "Failed to open " << path << "\n";
return;
}
std::string line;
while (std::getline(file, line)) {
for (const auto& c : line) {
if (c == 'a') { na_++; }
if (c == 'b') { nb_++; }
}
}
file.close();
}
void Processor::ProcessDirectory(std::string path) {
for (const auto& entry : std::filesystem::directory_iterator(path)) {
queue_.emplace_back(entry.path().string(), !entry.is_directory());
}
}
int main(int argc, char **argv) {
if (argc < 2) {
fprintf(stderr, "Need path to a directory");
exit(EXIT_FAILURE);
}
Processor p{argv[1]};
p.Run();
p.PrintStats();
}I am using std::filesystem utilities to walk the directory, putting every
entry into a queue of entries to process later (breadth-first search). If an
entry from the queue is a file, I just count the number of occurrences of
'a'/'b' characters. It is trivial to extend to count other
occurrences, or to compute a checksum, or anything else, but I want to do
minimal processing to ensure this program is as much disk-bound as possible.
For the parallel program, I need to use a thread pool, to ensure that the number of executing threads is exactly the number of cores my system has:
diff --git a/fssc.cc b/fsmc.cc
index c9f4bbc..d7872f0 100644
--- a/fssc.cc
+++ b/fsmc.cc
@@ -1,7 +1,11 @@
+#include <condition_variable>
#include <deque>
#include <filesystem>
#include <fstream>
#include <iostream>
+#include <mutex>
+#include <thread>
+#include <vector>
struct PathEntry {
std::string path;
@@ -19,15 +23,24 @@ class Processor {
void Run();
void PrintStats();
private:
+ void ProcessLoop();
void ProcessFile(std::string path);
void ProcessDirectory(std::string path);
+ std::mutex mn_;
int na_, nb_;
+
+ std::mutex mq_;
+ std::condition_variable cv_;
std::deque<PathEntry> queue_;
+ int nf_;
+
+ std::vector<std::thread> threads_;
};
Processor::Processor(std::string rootDir) : na_(0), nb_(0) {
queue_.emplace_back(rootDir, false);
+ nf_ = 1;
}
Processor::~Processor() {
@@ -35,21 +48,48 @@ Processor::~Processor() {
}
void Processor::Run() {
- while (!queue_.empty()) {
- PathEntry entry = queue_.front();
- queue_.pop_front();
+ const int num_threads = std::thread::hardware_concurrency();
+
+ threads_.resize(num_threads);
+ for (int i = 0; i < num_threads; i++) {
+ threads_.emplace_back(&Processor::ProcessLoop, this);
+ }
+
+ for (auto& thread : threads_) {
+ if (thread.joinable()) {
+ thread.join();
+ }
+ }
+ threads_.clear();
+}
+
+void Processor::ProcessLoop() {
+ while (true) {
+ PathEntry entry;
+ {
+ std::unique_lock<std::mutex> lock(mq_);
+ cv_.wait(lock, [this] { return !queue_.empty() || !nf_; });
+ if (!nf_) { break; }
+ entry = queue_.front();
+ queue_.pop_front();
+ }
if (entry.isFile) {
ProcessFile(entry.path);
} else {
ProcessDirectory(entry.path);
}
+ {
+ std::unique_lock<std::mutex> lock(mq_);
+ nf_--;
+ cv_.notify_all();
+ }
}
}
void Processor::ProcessFile(std::string path) {
std::fstream file(path, std::ios::in);
if (!file.is_open()) {
@@ -57,20 +97,27 @@ void Processor::ProcessFile(std::string path) {
return;
}
+ int na = 0, nb = 0;
std::string line;
while (std::getline(file, line)) {
for (const auto& c : line) {
- if (c == 'a') { na_++; }
- if (c == 'b') { nb_++; }
+ if (c == 'a') { na++; }
+ if (c == 'b') { nb++; }
}
}
file.close();
+
+ std::unique_lock<std::mutex> lock(mn_);
+ na_ += na;
+ nb_ += nb;
}
void Processor::ProcessDirectory(std::string path) {
for (const auto& entry : std::filesystem::directory_iterator(path)) {
+ std::unique_lock<std::mutex> lock(mq_);
queue_.emplace_back(entry.path().string(), !entry.is_directory());
+ nf_++;
}
}The diff is quite large, but it can be summarized as adding a few more
includes, adding synchronization primitives and threading constructs, moving
the processing code from Run into ProcessLoop, and small changes
to the main processing functions to ensure minimal locking (i.e., in the
ProcessFile function we first compute the character occurrences into
local variables and then merge these to the class members only at the end).
Compilation is trivial here too:
g++ -Wall -Wextra -O3 fssc.cc -o fssc
g++ -Wall -Wextra -O3 fsmc.cc -o fsmcNote: Initially, I was planning to write this suite in C, too. However, handling error cases from the POSIX API made the control flow very obfuscated and I had some race conditions. Switching to C++ allowed me to simplify the control flow as well as run the code under sanitizers to detect issues:
g++ -Wall -Wextra -O -g -fsanitize=thread fsmc.cc -o fsmc -ltsan
g++ -Wall -Wextra -O -g -fsanitize=address fsmc.cc -o fsmc -lasan
g++ -Wall -Wextra -O -g -fsanitize=leak fsmc.cc -o fsmc -llsanExperimental results 🔗
We have 4 programs: mmsc, mmmc, fssc and fsmc. The mm.. ones are
CPU-bound, the fs.. ones are I/O-bound. The ..sc ones are single-threaded
whereas the ..mc ones run on every available CPU core.
The I/O-bound programs need to run both immediately after a reboot (cold filesystem cache) and after 4 repeated runs. That is, for the warm filesystem cache I will report the runtime after the fifth run.
For the I/O-bound programs, I am using a clone of the TensorFlow
repository at commit 7099ad591878eb549574ef5e985180588eed9aca. In fact, I am
creating 5 copies of the same checkout:
tf/
├── 1
│ └── ...tf_checkout...
├── 2
│ └── ...tf_checkout...
├── 3
│ └── ...tf_checkout...
├── 4
│ └── ...tf_checkout...
└── 5
└── ...tf_checkout...For each experiment, we run 5 trials recording the running time as given by
/usr/env/bin time. I am picking 5 trials as that makes it easier to
recover the quartiles from the data as the 2nd, 3rd and 4th sorted
measurements. This will make it easy to get box plots to summarize
the results. Next number of trials where this property would show up would be
11 experiments, but that is more than double and will take much too long to
get all the data for that case. The results will also be published in table
format.
Since battery levels might also impact performance, I am considering 3 different scenarios: battery charged at least 90%, battery between 40% and 60% charge and battery charge less than 15%. For each of these, I am measuring the time with the charger plugged in and with the laptop unplugged.
These programs are run without anything else running on the system, except a user session in the GNOME graphical environment and a GNOME terminal tab from which these start. I will be playing Zelda while these run :)
With these details, it is time to run all experiments and record the results. Next subsection has all data tables, but you can jump to the graphs one if you don’t want to see all the tiny details.
Table of results 🔗
We have a total of 540 experiments to run, as described below, grouped by type of experiment. In all of the tables below, the times are given in seconds.
CPU bound experiments 🔗
We group the tables based on power level. First, for battery charge at least 90% we have the following results:
| exp# | mmsc unplugged |
mmsc plugged |
mmmc unplugged |
mmmc plugged |
|---|---|---|---|---|
| 0 | 57.70 | 57.18 | 26.05 | 23.82 |
| 1 | 58.03 | 55.54 | 25.72 | 23.87 |
| 2 | 56.14 | 54.96 | 27.56 | 24.47 |
| 3 | 59.04 | 55.05 | 24.51 | 26.18 |
| 4 | 56.25 | 54.53 | 23.90 | 24.92 |
| mean | 57.43 | 55.45 | 25.55 | 24.65 |
| stddev | ±1.23 | ±1.03 | ±1.43 | ±0.97 |
| exp# | mmsc unplugged |
mmsc plugged |
mmmc unplugged |
mmmc plugged |
|---|---|---|---|---|
| 0 | 77.46 | 81.27 | 42.38 | 41.89 |
| 1 | 75.16 | 77.56 | 41.08 | 42.11 |
| 2 | 77.09 | 76.31 | 42.07 | 42.20 |
| 3 | 76.61 | 76.18 | 42.06 | 42.29 |
| 4 | 76.58 | 76.84 | 43.54 | 41.77 |
| mean | 76.58 | 77.63 | 42.23 | 42.05 |
| stddev | ±0.87 | ±2.11 | ±0.88 | ±0.22 |
| exp# | mmsc unplugged |
mmsc plugged |
mmmc unplugged |
mmmc plugged |
|---|---|---|---|---|
| 0 | 109.95 | 111.68 | 46.04 | 47.44 |
| 1 | 112.24 | 110.45 | 45.52 | 48.16 |
| 2 | 111.19 | 111.61 | 45.67 | 46.13 |
| 3 | 109.99 | 110.19 | 46.11 | 46.31 |
| 4 | 101.12 | 109.54 | 45.86 | 45.96 |
| mean | 108.90 | 110.69 | 45.84 | 46.80 |
| stddev | ±4.45 | ±0.93 | ±0.25 | ±0.96 |
For battery charge around 50% (between 40% and 60%), we have the following results:
| exp# | mmsc unplugged |
mmsc plugged |
mmmc unplugged |
mmmc plugged |
|---|---|---|---|---|
| 0 | 49.57 | 50.15 | 26.77 | 27.72 |
| 1 | 49.47 | 49.92 | 26.01 | 26.39 |
| 2 | 50.14 | 49.93 | 27.38 | 24.91 |
| 3 | 49.61 | 49.91 | 26.36 | 26.17 |
| 4 | 50.15 | 50.15 | 25.25 | 23.80 |
| mean | 49.79 | 50.01 | 26.35 | 25.80 |
| stddev | ±0.33 | ±0.13 | ±0.80 | ±1.50 |
| exp# | mmsc unplugged |
mmsc plugged |
mmmc unplugged |
mmmc plugged |
|---|---|---|---|---|
| 0 | 70.00 | 71.94 | 41.96 | 42.69 |
| 1 | 69.64 | 70.13 | 41.77 | 42.41 |
| 2 | 69.45 | 70.67 | 42.55 | 42.33 |
| 3 | 69.63 | 70.11 | 41.92 | 41.83 |
| 4 | 69.91 | 69.95 | 42.50 | 42.39 |
| mean | 69.73 | 70.56 | 42.14 | 42.33 |
| stddev | ±0.23 | ±0.82 | ±0.36 | ±0.31 |
| exp# | mmsc unplugged |
mmsc plugged |
mmmc unplugged |
mmmc plugged |
|---|---|---|---|---|
| 0 | 108.86 | 109.43 | 46.61 | 46.15 |
| 1 | 107.89 | 108.15 | 46.22 | 45.65 |
| 2 | 108.67 | 109.09 | 45.79 | 46.05 |
| 3 | 107.60 | 109.67 | 45.78 | 46.23 |
| 4 | 107.75 | 109.09 | 46.00 | 46.29 |
| mean | 108.15 | 109.09 | 46.08 | 46.07 |
| stddev | ±0.57 | ±0.58 | ±0.35 | ±0.25 |
Finally, for battery charge below 15%, we have the following results:
| exp# | mmsc unplugged |
mmsc plugged |
mmmc unplugged |
mmmc plugged |
|---|---|---|---|---|
| 0 | 50.32 | 50.24 | 25.78 | 29.39 |
| 1 | 50.11 | 50.19 | 23.91 | 29.96 |
| 2 | 49.90 | 50.14 | 24.40 | 28.98 |
| 3 | 50.16 | 49.59 | 25.57 | 27.01 |
| 4 | 49.99 | 50.28 | 24.32 | 26.17 |
| mean | 50.10 | 50.09 | 24.80 | 28.30 |
| stddev | ±0.16 | ±0.28 | ±0.83 | ±1.63 |
| exp# | mmsc unplugged |
mmsc plugged |
mmmc unplugged |
mmmc plugged |
|---|---|---|---|---|
| 0 | 72.26 | 69.97 | 41.90 | 42.17 |
| 1 | 70.06 | 69.70 | 42.37 | 42.30 |
| 2 | 69.50 | 70.21 | 41.65 | 42.04 |
| 3 | 71.30 | 70.94 | 42.81 | 42.88 |
| 4 | 70.53 | 70.20 | 41.44 | 42.87 |
| mean | 70.73 | 70.20 | 42.03 | 42.45 |
| stddev | ±1.08 | ±0.46 | ±0.56 | ±0.40 |
| exp# | mmsc unplugged |
mmsc plugged |
mmmc unplugged |
mmmc plugged |
|---|---|---|---|---|
| 0 | 108.16 | 108.71 | 46.58 | 46.52 |
| 1 | 107.38 | 107.97 | 46.08 | 45.78 |
| 2 | 108.51 | 108.79 | 45.95 | 46.86 |
| 3 | 108.30 | 107.51 | 46.04 | 48.65 |
| 4 | 108.19 | 108.61 | 46.23 | 46.99 |
| mean | 108.11 | 108.32 | 46.18 | 46.96 |
| stddev | ±0.43 | ±0.56 | ±0.25 | ±1.06 |
Disk bound experiments 🔗
Here, we have one additional dimension to consider, as discussed above: cold vs warm CPU cache. Since it is easier to run the experiment 5 times after a reboot and record the first and 5th running time, the table headers are changed.
First, battery level at at least 90%, but laptop being unplugged:
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 168.35 | 5.78 | 123.84 | 0.89 |
| 1 | 155.55 | 5.76 | 125.73 | 0.89 |
| 2 | 156.85 | 5.80 | 119.33 | 0.90 |
| 3 | 154.62 | 5.68 | 120.71 | 0.89 |
| 4 | 156.76 | 5.74 | 130.20 | 0.89 |
| mean | 158.43 | 5.75 | 123.96 | 0.89 |
| stddev | ±5.62 | ±0.05 | ±4.30 | ±0.00 |
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 169.34 | 5.91 | 135.37 | 0.96 |
| 1 | 170.75 | 5.95 | 130.39 | 0.96 |
| 2 | 172.31 | 6.01 | 127.55 | 0.96 |
| 3 | 168.21 | 5.95 | 131.58 | 0.95 |
| 4 | 170.00 | 5.88 | 130.77 | 0.96 |
| mean | 170.12 | 5.94 | 131.13 | 0.96 |
| stddev | ±1.54 | ±0.05 | ±2.81 | ±0.00 |
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 155.16 | 17.83 | 136.08 | 3.06 |
| 1 | 175.67 | 17.97 | 134.45 | 3.06 |
| 2 | 177.98 | 17.95 | 125.15 | 3.04 |
| 3 | 177.99 | 17.86 | 129.30 | 3.04 |
| 4 | 171.98 | 18.02 | 140.17 | 3.05 |
| mean | 171.76 | 17.93 | 133.03 | 3.05 |
| stddev | ±9.60 | ±0.08 | ±5.88 | ±0.01 |
Next, battery level is still at least 90%, but laptop is now plugged in:
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 161.73 | 5.75 | 128.15 | 0.89 |
| 1 | 147.05 | 5.67 | 122.90 | 0.90 |
| 2 | 158.90 | 5.69 | 121.49 | 0.88 |
| 3 | 159.09 | 5.68 | 118.38 | 0.89 |
| 4 | 161.17 | 5.73 | 120.73 | 0.89 |
| mean | 157.59 | 5.70 | 122.33 | 0.89 |
| stddev | ±6.02 | ±0.03 | ±3.64 | ±0.01 |
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 171.23 | 6.02 | 131.74 | 0.97 |
| 1 | 170.97 | 5.99 | 130.25 | 0.96 |
| 2 | 171.79 | 5.91 | 131.59 | 0.96 |
| 3 | 166.84 | 5.96 | 136.06 | 0.95 |
| 4 | 168.40 | 5.99 | 128.46 | 0.96 |
| mean | 169.85 | 5.98 | 131.62 | 0.96 |
| stddev | ±2.13 | ±0.04 | ±2.81 | ±0.01 |
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 177.37 | 18.05 | 128.00 | 3.06 |
| 1 | 179.47 | 17.93 | 140.77 | 3.04 |
| 2 | 157.02 | 18.16 | 138.80 | 3.05 |
| 3 | 183.07 | 17.90 | 133.47 | 3.06 |
| 4 | 176.67 | 18.05 | 128.67 | 3.07 |
| mean | 174.72 | 18.02 | 133.94 | 3.06 |
| stddev | ±10.20 | ±0.11 | ±5.78 | ±0.01 |
Battery level between 40% and 60%, unplugged:
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 161.07 | 5.74 | 129.30 | 0.89 |
| 1 | 157.96 | 5.85 | 131.66 | 0.89 |
| 2 | 156.47 | 5.78 | 116.34 | 0.89 |
| 3 | 161.89 | 5.74 | 122.03 | 0.88 |
| 4 | 155.81 | 5.69 | 123.49 | 0.89 |
| mean | 158.64 | 5.76 | 124.56 | 0.89 |
| stddev | ±2.72 | ±0.06 | ±6.08 | ±0.00 |
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 173.35 | 6.02 | 133.07 | 0.96 |
| 1 | 171.36 | 5.87 | 128.53 | 0.96 |
| 2 | 171.21 | 5.85 | 127.21 | 0.96 |
| 3 | 169.47 | 6.01 | 126.63 | 0.96 |
| 4 | 171.23 | 5.92 | 128.11 | 0.97 |
| mean | 171.32 | 5.93 | 128.71 | 0.96 |
| stddev | ±1.38 | ±0.08 | ±2.55 | ±0.00 |
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 159.98 | 18.00 | 119.61 | 3.06 |
| 1 | 167.22 | 18.07 | 142.60 | 3.04 |
| 2 | 171.16 | 17.92 | 123.32 | 3.06 |
| 3 | 148.51 | 17.88 | 132.03 | 3.03 |
| 4 | 164.17 | 17.95 | 130.10 | 3.05 |
| mean | 162.21 | 17.96 | 129.53 | 3.05 |
| stddev | ±8.69 | ±0.07 | ±8.87 | ±0.01 |
Battery level around 50%, plugged in:
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 164.12 | 5.78 | 125.10 | 0.90 |
| 1 | 157.97 | 5.70 | 122.21 | 0.89 |
| 2 | 162.85 | 5.84 | 123.66 | 0.89 |
| 3 | 160.92 | 5.73 | 116.28 | 0.89 |
| 4 | 158.15 | 5.73 | 130.27 | 0.89 |
| mean | 160.80 | 5.76 | 123.50 | 0.89 |
| stddev | ±2.75 | ±0.06 | ±5.06 | ±0.00 |
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 171.64 | 5.95 | 132.16 | 0.95 |
| 1 | 170.76 | 5.93 | 133.13 | 0.96 |
| 2 | 169.47 | 5.94 | 130.70 | 0.97 |
| 3 | 172.21 | 5.92 | 127.77 | 0.96 |
| 4 | 171.19 | 5.85 | 130.33 | 0.96 |
| mean | 171.05 | 5.92 | 130.82 | 0.96 |
| stddev | ±1.04 | ±0.04 | ±2.04 | ±0.01 |
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 162.27 | 17.95 | 124.80 | 3.05 |
| 1 | 180.24 | 17.97 | 130.75 | 3.05 |
| 2 | 189.13 | 18.02 | 124.17 | 3.05 |
| 3 | 169.28 | 18.02 | 130.15 | 3.07 |
| 4 | 178.19 | 17.93 | 145.32 | 3.06 |
| mean | 175.82 | 17.98 | 131.04 | 3.06 |
| stddev | ±10.35 | ±0.04 | ±8.53 | ±0.01 |
Low battery mode (<15%), unplugged:
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 158.95 | 5.78 | 128.06 | 0.89 |
| 1 | 155.53 | 5.76 | 125.94 | 0.89 |
| 2 | 152.08 | 5.72 | 117.40 | 0.89 |
| 3 | 163.39 | 5.71 | 120.54 | 0.89 |
| 4 | 159.04 | 5.72 | 120.36 | 0.89 |
| mean | 157.80 | 5.74 | 122.46 | 0.89 |
| stddev | ±4.24 | ±0.03 | ±4.39 | ±0.00 |
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 172.05 | 5.95 | 130.38 | 0.96 |
| 1 | 170.80 | 5.92 | 127.09 | 0.96 |
| 2 | 168.64 | 5.94 | 130.26 | 0.97 |
| 3 | 171.30 | 5.96 | 130.63 | 0.96 |
| 4 | 171.77 | 5.83 | 129.02 | 0.94 |
| mean | 170.91 | 5.92 | 129.48 | 0.96 |
| stddev | ±1.36 | ±0.05 | ±1.47 | ±0.01 |
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 158.65 | 17.82 | 124.76 | 3.06 |
| 1 | 163.10 | 17.86 | 140.31 | 3.05 |
| 2 | 175.70 | 18.02 | 140.11 | 3.03 |
| 3 | 174.62 | 17.86 | 133.07 | 3.05 |
| 4 | 190.53 | 17.92 | 132.39 | 3.06 |
| mean | 172.52 | 17.90 | 134.13 | 3.05 |
| stddev | ±12.45 | ±0.08 | ±6.44 | ±0.01 |
Low batter mode but charging:
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 162.68 | 5.80 | 116.55 | 0.89 |
| 1 | 163.11 | 5.73 | 122.43 | 0.89 |
| 2 | 158.93 | 5.79 | 121.43 | 0.89 |
| 3 | 164.82 | 5.77 | 120.53 | 0.89 |
| 4 | 158.61 | 5.73 | 119.52 | 0.91 |
| mean | 161.63 | 5.76 | 120.09 | 0.89 |
| stddev | ±2.73 | ±0.03 | ±2.25 | ±0.01 |
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 169.83 | 5.91 | 132.51 | 0.96 |
| 1 | 168.34 | 5.99 | 128.20 | 0.95 |
| 2 | 171.16 | 5.96 | 130.13 | 0.97 |
| 3 | 171.31 | 5.93 | 135.36 | 0.95 |
| 4 | 168.80 | 5.92 | 128.76 | 0.95 |
| mean | 169.89 | 5.94 | 130.99 | 0.96 |
| stddev | ±1.34 | ±0.03 | ±2.95 | ±0.01 |
| exp# | fssc cold |
fssc warm |
fsmc cold |
fsmc warm |
|---|---|---|---|---|
| 0 | 179.05 | 17.73 | 124.28 | 3.03 |
| 1 | 167.63 | 17.92 | 138.58 | 3.05 |
| 2 | 180.79 | 17.87 | 129.86 | 3.03 |
| 3 | 191.26 | 17.99 | 130.79 | 3.04 |
| 4 | 165.90 | 17.83 | 126.36 | 3.04 |
| mean | 176.93 | 17.87 | 129.97 | 3.04 |
| stddev | ±10.40 | ±0.10 | ±5.48 | ±0.01 |
Graphs and summaries 🔗
Looking at the data we observe that battery level and charging status are not influencing performance. Up to measurement error, the data in all other dimensions matches regardless of how charged my laptop’s battery is or whether I am currently charging it or not. The only impact is that battery saver kicks in when battery level goes below a threshold (10%), at which point power mode is switched to power save mode. However, this can be switched back to performance if so desired.
Since the data is independent of battery status, I will combine all matching measurements. This means that I could have also ran only 3 rounds of each experiment, since I would determine the quartiles from the entire data, integrating over battery status. That would have been a nearly 40% reduction in experimentation time, but it would have required knowing the future or changing the experiment as data was arriving (or, a better experimental design where I would not set up to study all cartesian combinations from the start – the field of experimental design is something I want to touch in a separate (set of) article(s)).
If we combine all the data, we have the following summary table where all values are in seconds. The experiments are grouped based on binary, disk cache status (for disk-bound experiments only) and power mode:
| experiment | mean | stddev | Q25 | Q50 | Q75 | ||
|---|---|---|---|---|---|---|---|
mmsc |
performance | 52.15 | ±3.21 | 49.95 | 50.16 | 55.03 | |
| balanced | 72.57 | ±3.44 | 69.98 | 70.60 | 76.28 | ||
| power-save | 108.88 | ±1.96 | 108.15 | 108.75 | 109.88 | ||
mmmc |
performance | 25.91 | ±1.67 | 24.48 | 25.90 | 26.68 | |
| balanced | 42.21 | ±0.48 | 41.91 | 42.19 | 42.41 | ||
| power-save | 46.32 | ±0.70 | 45.95 | 46.12 | 46.47 | ||
fssc |
cold | performance | 159.15 | ±4.16 | 156.78 | 158.94 | 161.85 |
| balanced | 170.52 | ±1.49 | 169.47 | 171.07 | 171.35 | ||
| power-save | 172.33 | ±10.63 | 164.60 | 175.15 | 178.84 | ||
| warm | performance | 5.75 | ±0.05 | 5.72 | 5.74 | 5.78 | |
| balanced | 5.94 | ±0.05 | 5.91 | 5.94 | 5.96 | ||
| power-save | 17.94 | ±0.09 | 17.87 | 17.94 | 18.02 | ||
fsmc |
cold | performance | 122.82 | ±4.31 | 120.40 | 122.12 | 125.57 |
| balanced | 130.46 | ±2.50 | 128.48 | 130.36 | 131.70 | ||
| power-save | 131.94 | ±6.61 | 126.77 | 130.77 | 137.96 | ||
| warm | performance | 0.89 | ±0.01 | 0.89 | 0.89 | 0.89 | |
| balanced | 0.96 | ±0.01 | 0.96 | 0.96 | 0.96 | ||
| power-save | 3.05 | ±0.01 | 3.04 | 3.05 | 3.06 | ||
There are 3 main categories of results: the CPU-bound experiments, and the 2 disk-bound ones, with the 2 conditions on the filesystem caches. It turns out that these caches are quite efficient!
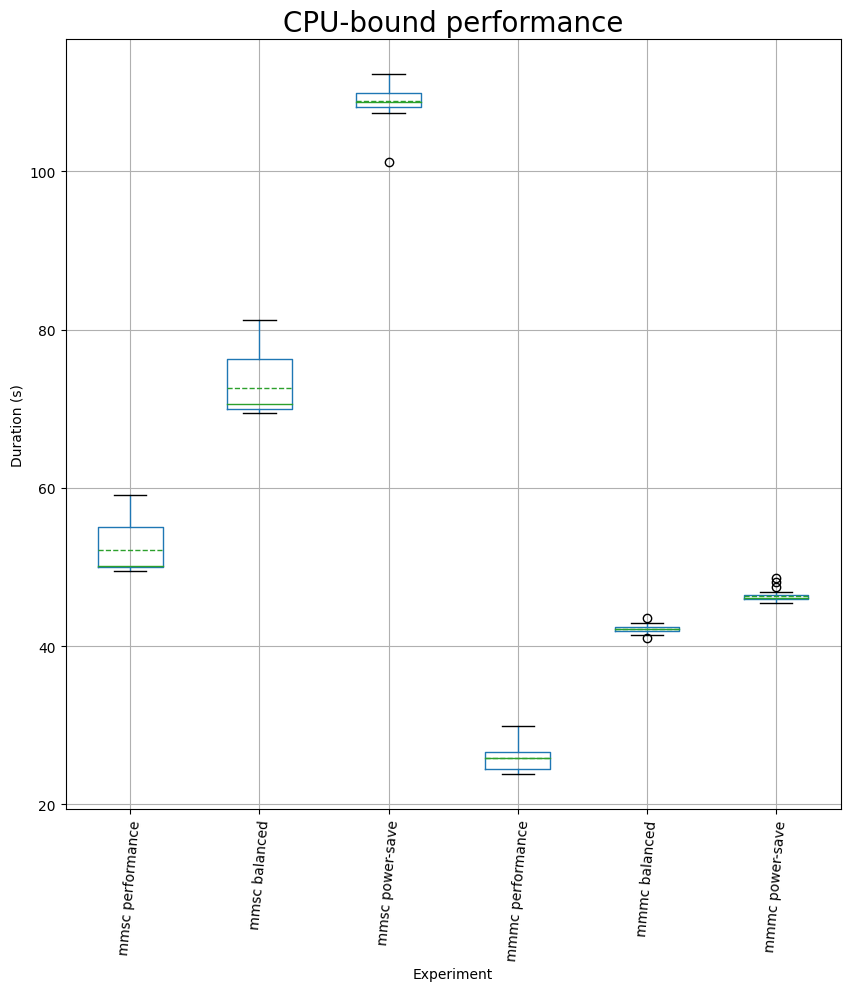
For the CPU-bound experiments, we first see that the multi-core one did not result in the expected speed improvement, in any of the cases (I was running on 8 cores, but the gains are around 2x). This is because we only implemented a naive parallelism scheme, maybe I’ll improve on this in another article and possibly repeat the experiment. The performance impact of switching from performance battery mode to the other 2 are quite severe: 39% / 63% additional time when switching to balanced and 109% / 78% when switching to power-save.
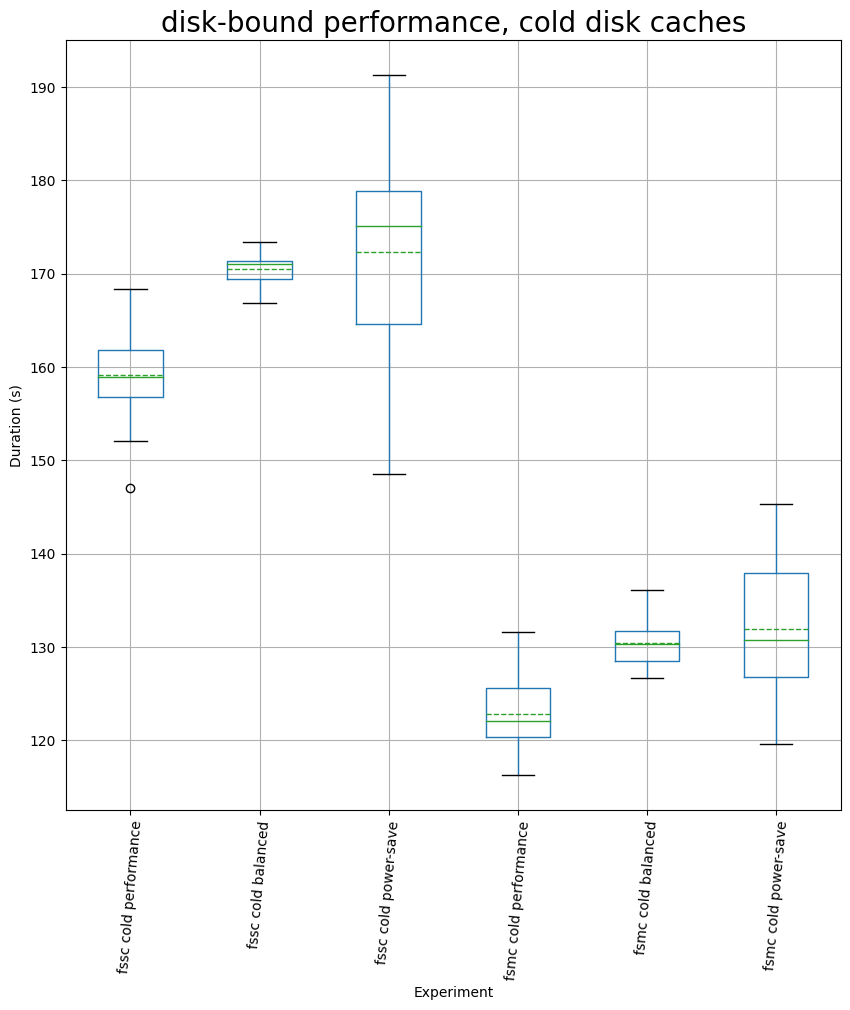
For the disk-bound runtimes, under a cold filesystem cache, the changes in power profiles are not significant: we can approximate them to be around 7% compared to performance mode, regardless of whether we run in single threaded mode or with maximum concurrency, regardless of whether we switch to balanced mode or to power-save.
On the case when the filesystem cache is completely warmed up, so we can expect most reads to be served from it, we have significant performance impact when using power-save mode: 212% more time in the single threaded case and 242% more time in the multi threaded one! The balanced mode is not giving a significant change in behavior.
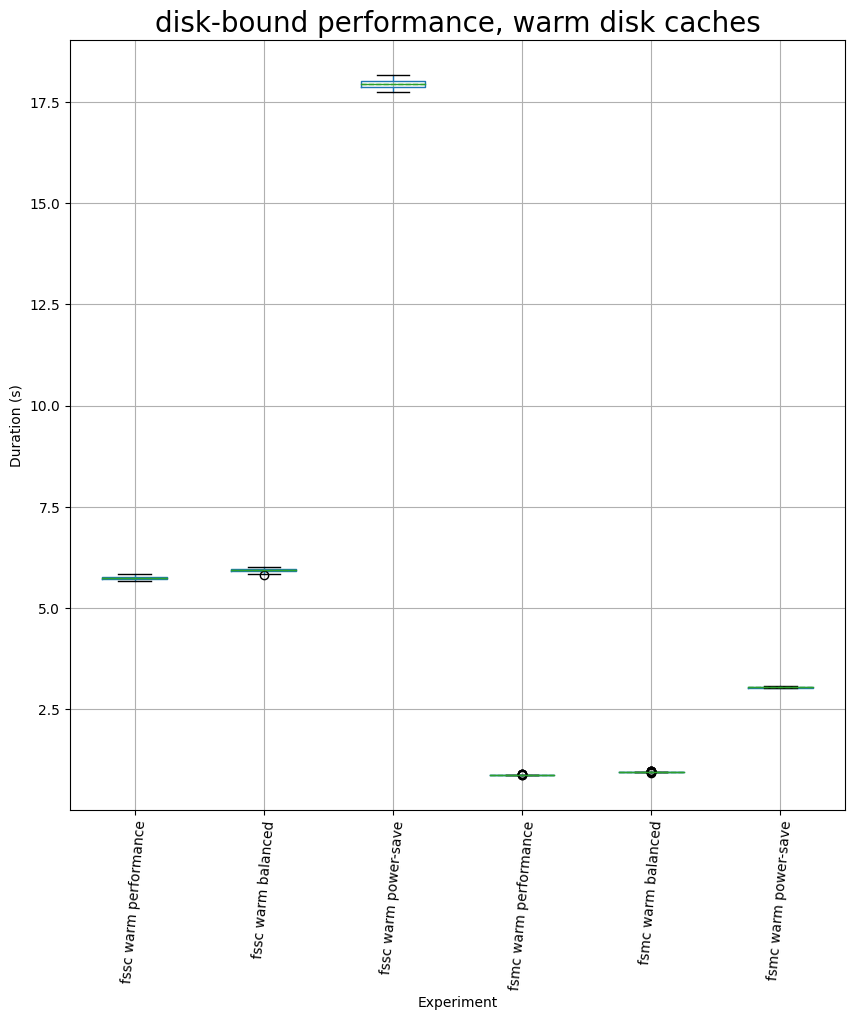
If the disk cache is warm, the runtime is extremely small, to the point where I am having doubts about whether running the code with multiple copies of TensorFlow repository (or multiple large repositories) might show different statistics. I might repeat this experiment later too.
Alternatively, if we look closer at the error bars in the disk-bound experiments, we can also state that battery power profile has no impact on the runtime of reading from disk. The observed differences are due to the small amount of CPU processing that we need to perform, plus HDD noise, and operating system tasks. If the filesystem cache is warm, then the ratio of time spent running on CPU vs waiting for I/O is larger, so the impact of the power-save mode is more visible.
I could devise a new experiment to test this (for another article), but reading documentation shows that only the CPU should be affected. This means that I also don’t need to run another suite of experiments to analyze networking impact. But, I might need to test how GPU acceleration is impacted. Will leave this for another time.
Comments:
There are 0 comments (add more):